к тому, что во все
Развитие компьютерной индустрии и информационных технологий привело к тому, что во все большем числе областей бизнеса обработка документов производится автоматически с помощью компьютеров. Чтобы быть пригодными для компьютерной обработки, данные оформляются в виде формального текста, т.е. текста на некотором формальном языке. Транслятор - это программа, осуществляющая обработку формального текста и перевод его в некоторое другое представление. Примерами трансляторов являются компиляторы и интерпретаторы языков программирования, XML-процессоры, браузеры HTML-страниц, системы поддержки специфицирования и моделирования, текстовые процессоры и издательские системы, серверы запросов СУБД и проч. Трансляторы используются при разработке ПО, при организации работы сетевых приложений, при создании разного рода распределенных информационных систем и т.д. Широкое распространение трансляторов, их повсеместное как прямое, так и косвенное использование в различных областях компьютерной индустрии, включая критические, обуславливает высокие требования к качеству трансляторов. Существует много разных подходов к достижению качества программного обеспечения (ПО). Одним из подходов является проведение аналитического доказательства корректности ПО. Вопросам теоретического обоснования корректности поведения компиляторов на основе использования различных логических исчислений посвящены, например, работы [], [], []. Однако, при разработке программных систем высокой сложности, какими являются реальные трансляторы, более практичным подходом является тестирование []. При тестировании встают две основные проблемы:
- Проблема систематического создания тестовых данных для испытания работы тестируемой системы во всех различных ситуациях.
- Проблема построения оракула для вынесения вердикта о корректности работы тестируемой системы.
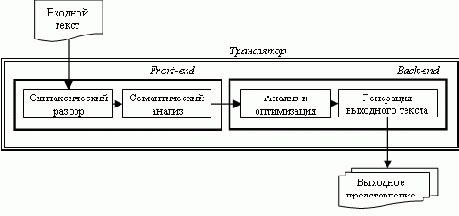
Поэтому очень актуальна проблема автоматизации как процесса создания тестовых данных, так и процедуры вынесения вердикта. Наиболее многообещающим в плане автоматизации подходом является тестирование на основе формальных спецификаций и моделей []. В трансляторах традиционно выделяют следующие функциональные блоки: front-end, осуществляющий синтаксический разбор и семантический анализ входного текста и построение его внутреннего представления, и back-end, осуществляющий дополнительный анализ входных данных, возможно, некоторые оптимизирующие преобразования, а также собственно генерацию выходного представления (см. Рис. 1).